- Core Thesis: The data annotation paradigm is shifting from manual crowdsourced human-labeling to programmatic, LLM-in-the-loop, and synthetic data feedback loops.
- Why It Matters: Traditional manual labeling cannot scale to meet the complex, specialized domain requirements (medical, legal, physics) of frontier AI models.
- Strategic Direction: Back programmatic labeling pipelines, active learning frameworks, and domain-specific expert curation networks that deliver high-fidelity data signals.
The foundation of any high-performing artificial intelligence system resides in the quality, consistency, and alignment of its training data. As frontier models transition from simple pattern recognition to complex reasoning and agentic workflows, the requirements for data curation have undergone a fundamental shift.
Historically, data labeling was treated as a low-margin commodity operation, outsourced to global crowdsourced workforces performing repetitive manual bounding-box or classification tasks. Today, as models hit the limits of public internet data, the industry is entering a new era where data annotation is an algorithmic and programmatic science.
Problem
AI data annotation and labeling solves a core operational bottleneck for developers transitioning from general text systems to specialized, vertical applications and physical-world agency. While basic 2D image and general web text data are largely commoditized, AI builders are hitting a severe data satiation point, where public web data is completely exhausted. The immediate bottleneck has shifted to acquiring, cleaning, and labeling high-cognitive domain datasets (such as medical scans or complex legal clauses) and multi-sensor spatial data (such as 3D LiDAR point clouds, egocentric video streams, and force-torque sensor inputs) required to train autonomous systems and embodied robotics.
Traditional crowdsourcing networks fail completely in this new paradigm. Generalist, low-wage workers paid per-click do not possess the clinical training to annotate medical scans, nor can they accurately label high-dimensional 3D spatial frames, leading to inconsistent, noisy labels that cause severe model hallucination and physical failures. AI developers are therefore trapped in a structural bind: maintaining in-house expert labeling teams is financially prohibitive and impossible to scale, while legacy manual-only labeling tools lack the programmatic orchestration and multi-sensor synchronization required to curate spatial-physical training data at the speed of active development.
Archetype
Hair on Fire (Help me now)
This market is characterized by an acute, high-velocity demand where developers are locked in a competitive race to ship reliable, high-conviction vertical models and physical robotic systems. Because a model's cognitive and physical capacity is mathematically bounded by the quality and accuracy of its input distribution, builders cannot simply bypass the data layer or rely on legacy crowdsourcing without experiencing catastrophic production failures. The absolute scarcity of specialized domain data and real-world multi-sensor sequences makes high-quality, programmatic labeling and expert-in-the-loop QA a continuous, non-negotiable mission-critical utility that teams must acquire immediately to survive in active development cycles.
Numbers
Tracing capital allocations within the AI infrastructure stack reveals the massive economic scale and rapid expansion of the data preparation sector.
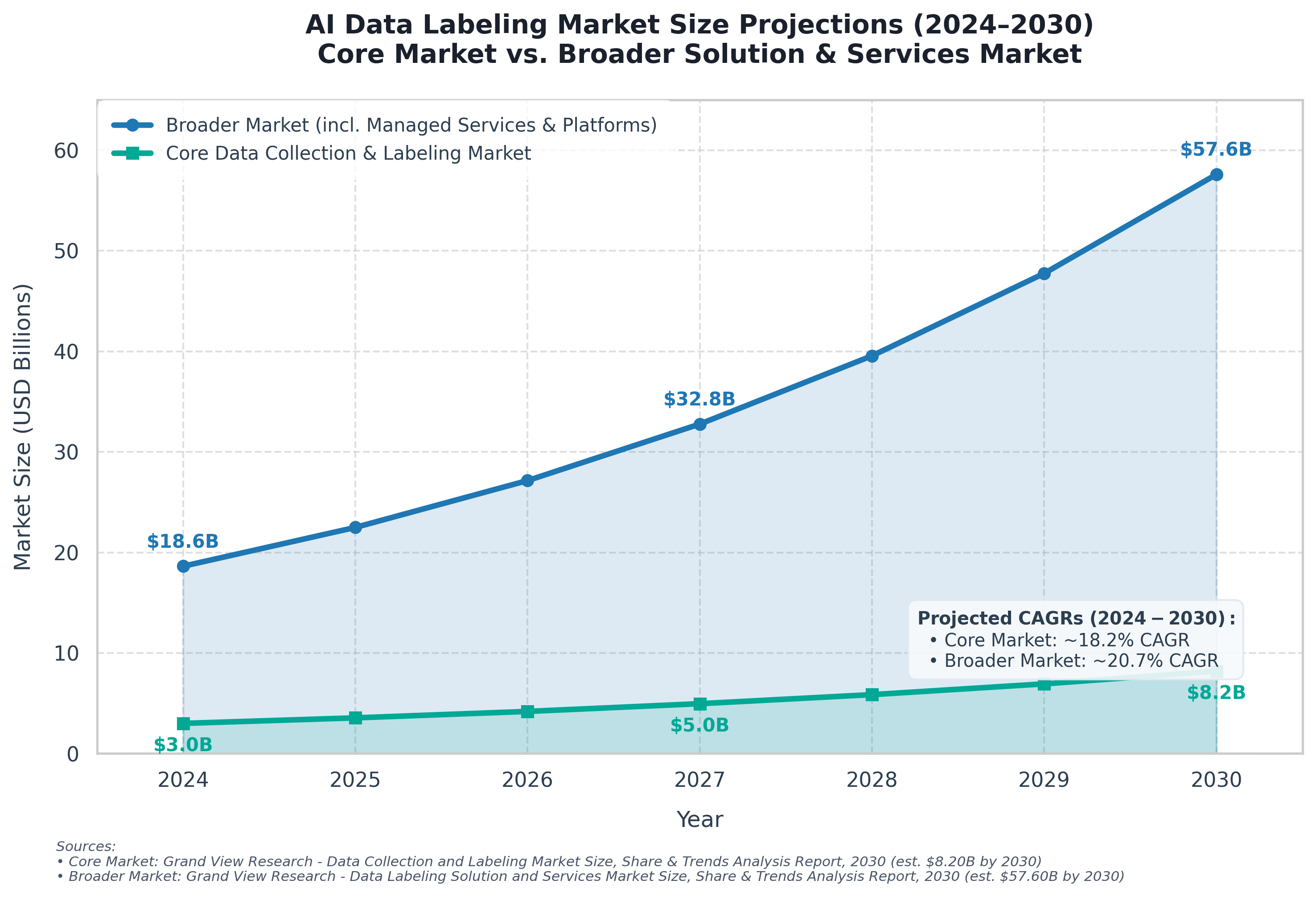
- Market Size: The global data annotation tool market is projected to reach USD 12.42 billion by 2031 according to Mordor Intelligence, while the broader services and solutions market is expected to scale to USD 57.63 billion by 2030 according to Grand View Research.
- CAGR: The industry is exhibiting highly aggressive trajectory, growing at a compound annual growth rate of 32.27% for software tools and 20.4% for broader annotation platforms through the forecast periods.
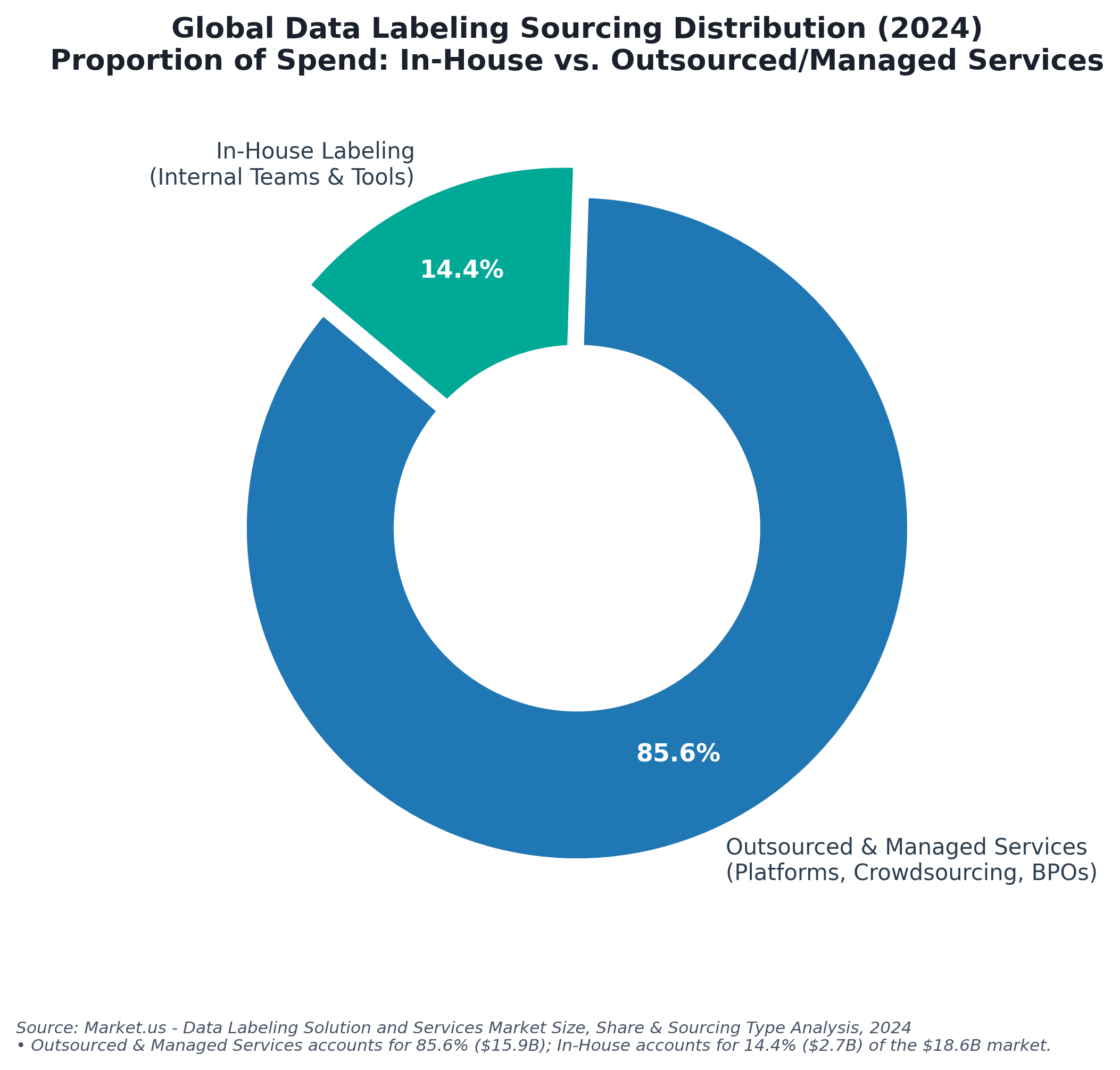
- Sourcing Efficiency: Outsourced and managed services capture 85.6% of the global data labeling spend, while only 14.4% is managed by internal in-house teams.
The compounding gap between core software tools and broader managed service layers shows that as AI models mature, enterprise spend pivots heavily toward sophisticated orchestration and quality-assurance services.
Maintaining internal, in-house labeling teams is highly resource-intensive and extremely difficult to scale. Consequently, outsourced and managed services capture the vast majority of the market share, accounting for 85.6% of global enterprise labeling spend, while only 14.4% is managed by internal teams. Enterprises increasingly rely on managed service providers who take full responsibility for accuracy SLAs and provide vetted domain-expert annotators.
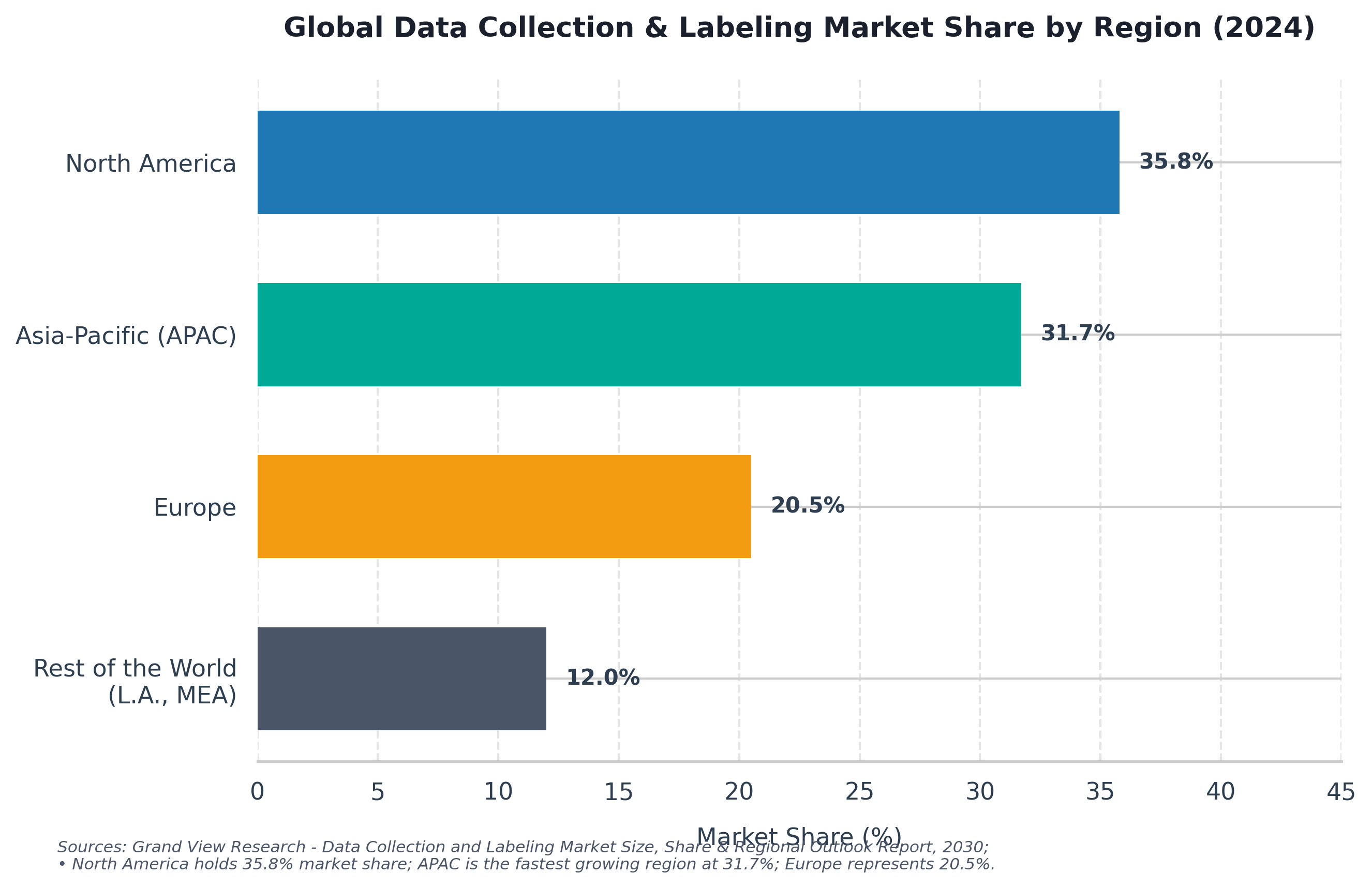
Geographically, the demand is heavily concentrated in regions with dense AI and technology hubs. North America represents the leading regional market share at 35.8% due to localized investments in autonomous vehicles and LLMs, followed closely by the Asia-Pacific region at 31.7%, which functions as the fastest-growing region due to a surge in local developer talent.
Other leading firms align on this hyper-growth profile: Research Nester values the data annotation tools market at USD 6.98 billion in 2025 with a 20.4% CAGR to 2035; Mordor Intelligence estimates the AI data labeling market at USD 1.89 billion in 2025 scaling to USD 2.32 billion in 2026; and TechSci Research projects the annotation market at USD 1.32 billion in 2024 expanding to USD 2.50 billion by 2030 with an 11.23% CAGR.
Players
The AI data annotation ecosystem is highly active, characterized by a structural division between software-first tooling platforms, large-scale managed services, and specialized programmatic and physical-world engines:
- Physical AI & Spatial Curation: Modern embodied intelligence requires specialized multi-sensor and spatial annotation. Scale AI launched its flagship "Data Engine for Physical AI" with a prototyping laboratory logging over 100,000 production hours of real-world hardware interaction. Encord specializes in multi-sensor fusion, temporal sequence labeling, and frame interpolation for warehouse automation. Segments.ai leads in overlaying 3D LiDAR point clouds onto 2D camera feeds, while Labellerr provides purpose-built annotation for egocentric wearable POV video streams used in humanoid robotics. Open-source toolkits like CVAT are widely adopted for 3D point-cloud bounding cuboids.
- High-Cognitive & Expert RLHF: Sourcing elite cognitive labor, such as medical doctors, corporate lawyers, and compilers engineers, is the current high-stakes bottleneck of frontier model alignment. Mercor leverages an AI-native vetting engine to source and onboard specialized experts in under 48 hours. Surge AI has aggressively scaled as a neutral, independent provider of high-fidelity human preference and instruction datasets, while Datacurve focuses heavily on SFT datasets for code generation. Centaur Labs focuses specifically on medical diagnostics by gamifying data labeling for verified clinicians.
- Enterprise Tooling & Infrastructure: Labelbox provides a comprehensive software suite with active learning loops, enabling internal development teams to curate and govern proprietary datasets. Others like SuperAnnotate offer robust collaborative environments for managing training data pipelines.
- Scale Managed Data Operations: Appen, TELUS Digital, Sama, CloudFactory, and iMerit remain dominant forces in large-scale, enterprise-grade managed data operations. They utilize highly secure, compliant physical cleanrooms and dedicated, professionally trained human-in-the-loop workforces.
- Programmatic & Heuristic Engines: Snorkel AI leads the programmatic labeling front, providing developer platforms that allow engineers to write programmatic labeling functions, such as heuristics, rules, and small models, to clean and label data programmatically.
- Crowdsourced & Task Platforms: Platforms like Hive and Toloka provide high-throughput crowdsourcing and automated content moderation, facilitating rapid execution of basic labeling tasks.
Takeaways
- The next structural battleground in data annotation is the transition from web-scraped text to physical-world egocentric video and 3D sensor fusion data, meaning the highest-moat platforms are those capable of programmatically cleaning and annotating complex spatial and temporal datasets for embodied robotics.
- Self-service annotation SaaS is experiencing rapid commoditization, which means buyers overwhelmingly prioritize managed service providers who guarantee accuracy SLAs and deliver fully completed, high-fidelity datasets.
- As AI models move past general-purpose web content to specialize in fields like medicine, law, and finance, generalist crowdsourced labor is obsolete, shifting defensibility toward networks of credentialed, domain-specific experts.
Sources & Citations
- Grand View Research: Data Collection and Labeling Market Report, 2030 - Comprehensive analysis detailing core data labeling market growth and regional demand distributions.
- Grand View Research: Data Labeling Solution and Services Market Size Report, 2030 - Documents the broader USD 57.63 billion services and solutions market expansion.
- Fortune Business Insights: Data Annotation Tool Market Size, Share & Growth Report - Industry analysis detailing the growth of the data annotation tool market to USD 14.26 billion by 2034.
- Research and Markets: Data Labeling Solution and Services Market Size & Sourcing Type Analysis - Analyzes the structural outsourcing trend and the 85.6% managed service dominance.
- Spherical Insights: Global Data Collection and Labeling Market Size, Share, and Regional Outlook - Tracks geographic regional market share and demand drivers across North America, Europe, and APAC.